
MySQL-03-DDL实践
MySQL-DDL实践
1.单表 - 基础语法 - select
判断 null 要用 is 不要用 = 符号distinct去重、as 取别名where子句,- 比较运算符
- 大于,小于,大于等于、小于等于、不等于
between...and...,区间in()显示在in列表的值,例如:in(90, 80);like’张%‘,not like ‘%元%’,模糊查询is null判断是否为空
- 逻辑运算符
- and 多条件同时成立
- or 多条件,任意一个成立
- not 不成立,例如:where not(chinese > 100);
- 比较运算符
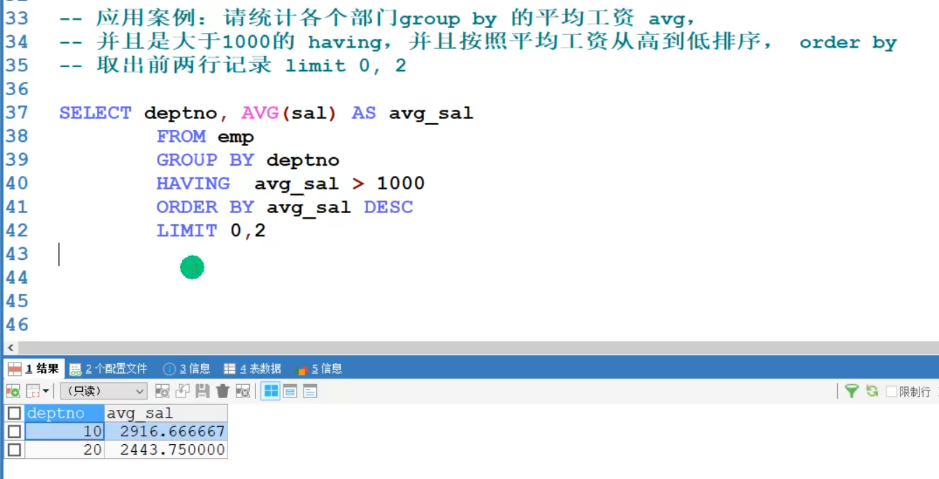
order by 列名,排序,默认 asc 升序(从低到高),desc 降序(从高到底)group by 列名,分组having,分组后条件子句
limit start, size;分页,从0开始。- size * (start - 1), size
执行顺序:
group by –> having –> order by –> limit
1 | select distinct * |
2.多表查询
- 多表查询,不添加
where条件,默认生成笛卡尔集(表与表数据数量相乘),产生大量无用数据 多表查询条件,不能少于表数量 - 1
1 | select name, sal from emp, dept where emp.deptno = dept.deptno; |
2.1 自连接
- 将单表看成多个相同的表
- 区别方式,通过取别名区分
1 | select worker.ename as '职员名', boss.ename as '上级名' |
2.2 子查询
- 一次查询的结果是下次查询的条件
- 子查询可以当作临时表使用
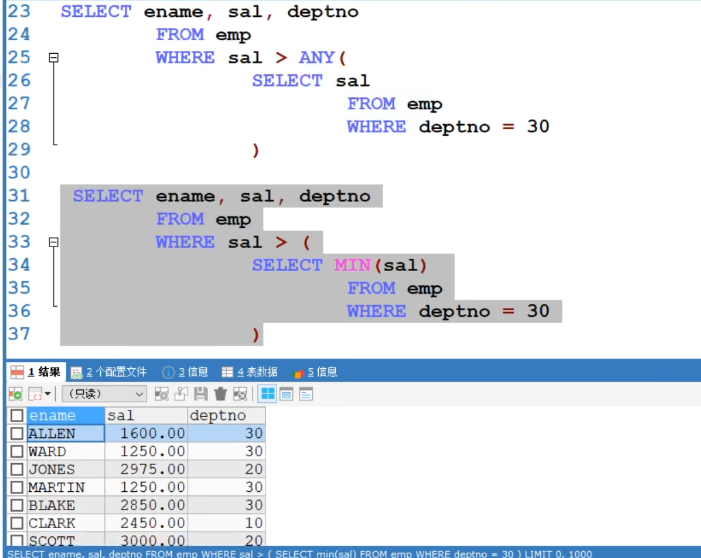
- any() 与 all()
- any(数组),符合数组中一个就返回true。(也可以使用min,只要大于最小的就可以)
- all(数组),符合数据所有的才返回true。(也可以使用max,只要大于最大的就可以)
1 | select * from emp |
2.2.1 小练习 - 子查询可以当作临时表使用
求出在各类商品中,最高价格的商品
分析:1.求出每类商品的最高价,2.再从最高价中的商品,找出最高的返回 – 子查询
1 | select goods_id, ecs_goods.cat_id, goods_name, shop_price |
- 求出与zhangsan,部门,岗位相同的员工,不包括本人
1 | select * |
- 查询和宋江数学、英语、语文成绩完全相同的学生 - 多列子查询
1 | select * |
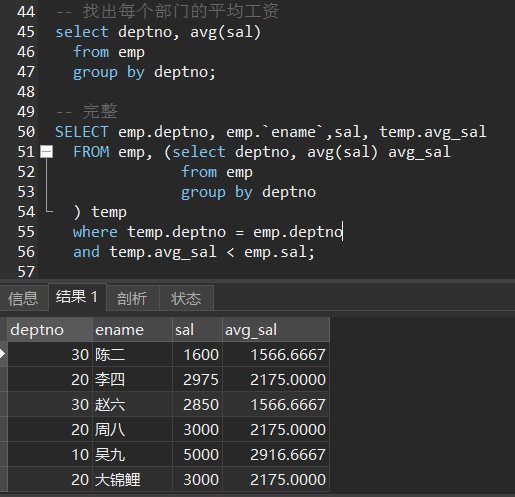
- 查询工资超过平均工资的员工
2.3 表复制
将一个表的数据复制到另一个表中
1
2insert into my_tab01(id, `name`, sal)
select id, `name`, sal from tab02自我复制
- 每次执行数据呈指数型增长
1
2insert into mytab01
select * from mytab01;表结构复制
1
create table mytab03 like emp;
2.4 合并查询
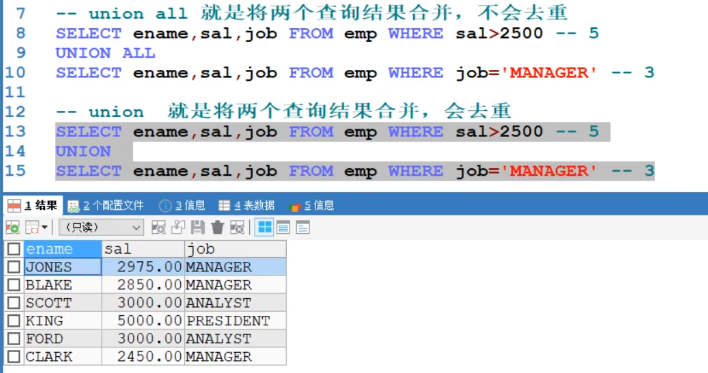
- union all,将量表数据合并,但不会去重
union,合并数据,会去重,常用- 两个查询语句中间使用
2.5 外连接
- 左外连接,左侧表完全显示,即使右表中没有也会以null形式显示。
表1 left jion 表2
- 右外连接,右侧表全部显示,即使左表中没有也会以null形式显示。
表1 right jion 表2
3.约束
3.1 主键约束 - primary key
- 默认
唯一,不为null - 单主键约束,直接在一个字段后定义
- 复合主键约束,在最后定义 primary key(字段1, 字段2)
- desc 表名,可以查看表约束
3.2 不为空约束 - not null
- 字段值,不能为null
3.3 值唯一约束 - unique
- ==注:==若字段指定了unique唯一约束,但没有指定not null,那么这个字段的值可以有多个null值
- 一个表可以有多个
- 字段 unique not null 效果类似于主键(pirmary key),但不是主键
3.4 外键约束 - foreign key
innodb支持,mysam不支持
若添加了外键约束,插入了超过被外键约束的字段值范围,那么会报错
- 如,班级表有1、2、3个班级,若学生表中以班级id为外键,添加了4班,则添加失败,因为编号4的班级不存在。
- 同样,想要直接删除编号3的班级,需要将学生表中所有是3号班的学生全部删除,才可以删除编号3的班级信息
最后统一定义
foreign key(字段) references 表(字段),如 foreign key(class_id) references 表(class_id)- 指向的外键必须在表2是个主键
- 若外键没有添加 not null,则可以存入null

3.5 范围约束 - check
mysql5.7不支持,支持语法校验,但不生效
5.7中,可以使用enum()替代,enum(‘男’,’女’)
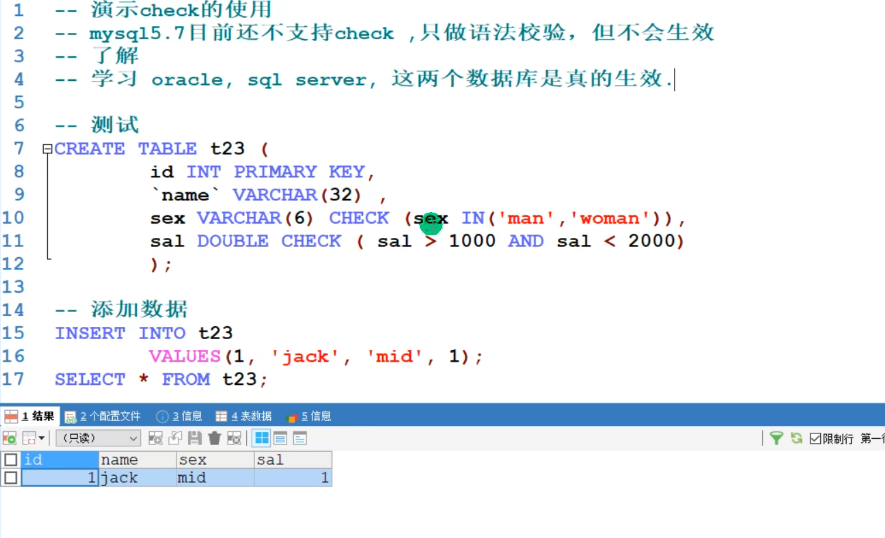
3.5.1 小练习

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30-- 商品表
create table goods(
`goods_id` varchar(30) primary key commit `商品号`,
`goods_name` varchar(20) commit `商品名`,
`unitprice` decimal(10,2) check(unitprice >= 1.0 and unitprice <= 9999.99) commit `单价`,
`category` varchar(20) commit `商品类别`,
`provider` varchar(20) commit `供应商`
);
-- 客户表
create table customer(
`customer_id` int primary key commit `客户号`,
`name` varchar(10) not null commit `客户名`,
`address` varchar(50) commit `住址`,
`email` varchar(20) unique commit `电邮`,
`sex` varchar(10) enum('男','女') commit `性别`,
`card_id` varchar(20) commit `身份证`
);
-- 订单表
create table purchase(
`order_id` varchar(30) primary key commit `订单号`,
`customer_id` int commit `客户号`,
`goods_id` varchar(30) commit `商品号`,
`nums` int commit `购买数量`
foreign key(goods_id) references goods(goods_id),
foreign key(customer_id) references customer(customer_id)
);
-- 返回表约束
desc goods;
desc customer;
desc purchase;
3.6 自增长 - auto_increment
- 字段名 整形 primary key auto_increment
- 常与primary key组合使用
4.索引 - index
查询索引:show indexs from 表名
索引类型:
主键索引(primary key),主键自动成为主键索引
唯一索引(unique)
普通索引(index)全文索引(fulltext),适用与MySAM
开发中考虑使用:全文搜索solr和
ElasticSearch(ES)
空间换时间,
索引占空间,提高查询速度(只对创建索引的字段生效)create index 索引名称 on 索引位置
create index empno_index on emp(empno)
4.1 索引问题
- 没有索引,进行全表扫描,一行一行的扫描
- 索引底层,二叉树,b+tree
- 索引代价:1.扩大磁盘占用。2.影响insert、update、delete操作【dml操作】效率,需要重新构建索引。
- 索引利大于弊,因为日常select操作远多于dml操作
4.2 添加索引
1 | 添加唯一索引 |
4.3 删除索引
- 删除索引需要先知道索引名,
- 通过show indexs from 表名
1 | 删除索引 |
4.4 修改索引
- 先删除,再添加
4.5 查询索引
1 | 查询索引 1. |
★4.6 索引规则
- 频繁作为查询条件的字段适合创建索引
- 字段值范围较小,不适合创建索引
- 更新频繁的字段,不适合创建索引
- 不会出现再where子句中的字段,不适合创建索引
5.事务 - transaction
概念:
事务用于保证数据的一致性,由一组相关的dml语句组成。执行一系列指令,
要么全部成功,要么全部失败,当作一个整体。数据库控制台基本操作:
start transaction:开始一个事务- savepoint 保存点名:设置保存点
- rollback to 保存点名:回退事务
rollback:回退全部事务commit:提交事务,结束事务,释放锁,数据生效
- 如果不开启事务,默认自动提交
- 开启事务,为创建保存点,可以执行rollback,回滚到事务开始的状态
- 保存点可以创建多个
- innodb支持事务,mysam不支持
★5.1 事务隔离级别
71_韩顺平MySQL_隔离级别演示1_哔哩哔哩_bilibili
查询事务隔离级别:select @@tx_isolation;- 查看系统隔离级别:select @@global.tx_isolation;
修改事务隔离级别:set session transaction isolation level 隔离级别定义事务与事务之间的隔离程度
读未提交(Read uncommitted),可能出现脏读,不可重复读,幻读读已提交(Read committed),解决脏读,可能出现不可重复读,幻读可重复读(Repeatable read),解决不可重复读,可能出现幻读,mysql默认隔离级别可串行化(Serializable),解决幻读,最高隔离级别,加锁,对同一个数据操作时,强制等待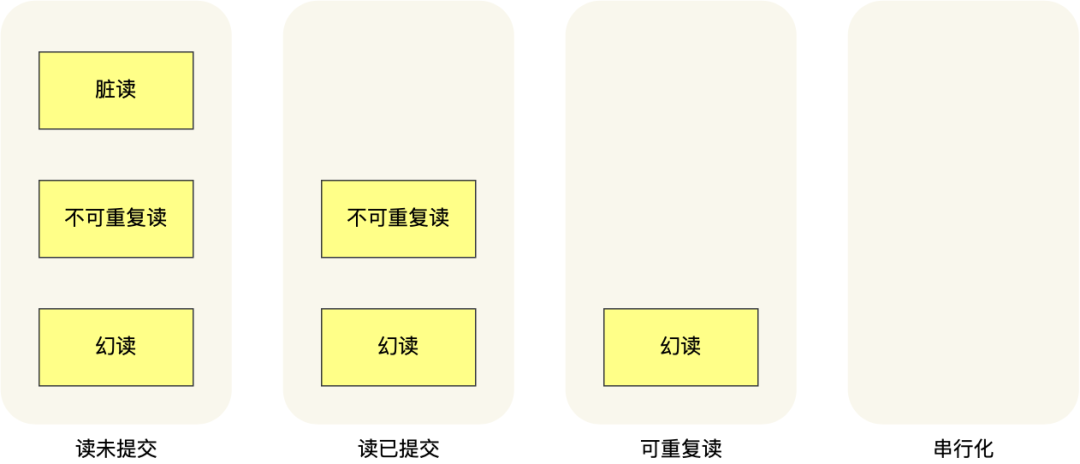
引发问题:脏读、不可重复读、幻读
脏读,一个事务读到另一个事务添加或修改或删除未提交的数据(insert,update,delete操作影响的数据)。- 当前状态:事务1
未提交,事务2也未提交,事务2出现数据读取不一致
- 当前状态:事务1
不可重复读,同一查询,由于其他事务修改或删除,导致每次返回不同的结果集。- 个人理解:因为我的事务
没有结束要保证数据与开启事务时数据一致。却读到了不同的数据. - 当前状态:事务1
已提交,事务2未提交,事务2出现读取数据不一致
- 个人理解:因为我的事务
幻读,同一查询,由于其他事务提交的插入操作,导致每次返回不同的结果集- 当前状态:事务1
已提交,事务2未提交,事务2出现读取数据不一致
- 当前状态:事务1
5.2 事务特性 - acid
原子性,指事务是不可分割的部分,事务中的操作,要么都发生,要么都不发生。一致性,事务必须使数据库从一个一致性状态变换到另一个一致性状态隔离性,多个用户并发访问时,数据库为每一个用户开启事务,不能被其他事务的操作数据所干扰,互相隔离持久性,事务一旦被提交,数据库中的数据改变就是永久性的,即使数据库发生故障也不应该对其产生任何影响
6.mysql表类型和存储引擎
存储引擎:MyISAM,innoDB,Memory
1 | 查看存储引擎: |
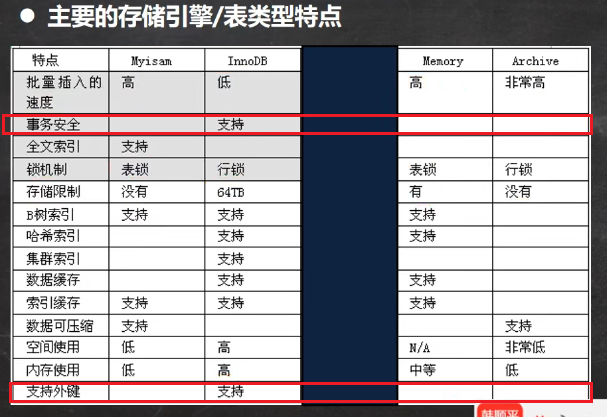
★6.1 存储引擎的区别
MyISAM、innoDB、Memory
- MyISAM
不支持事务、不支持外键,但其访问速度快,因为对事务完整性没有要求。是表级锁- InnoDB
支持事务,具有提交、回滚、崩溃恢复能力的事务,支持外键。InnoDb写的处理效率差,会占用更多的磁盘空间以保留数据和索引。是表级锁- Memory,是基于内存的存储引擎,速度极快,但重新连接,所有数据就清空,适合用户在线状态。适合变化频繁,且存入数据库中无意义的数据。

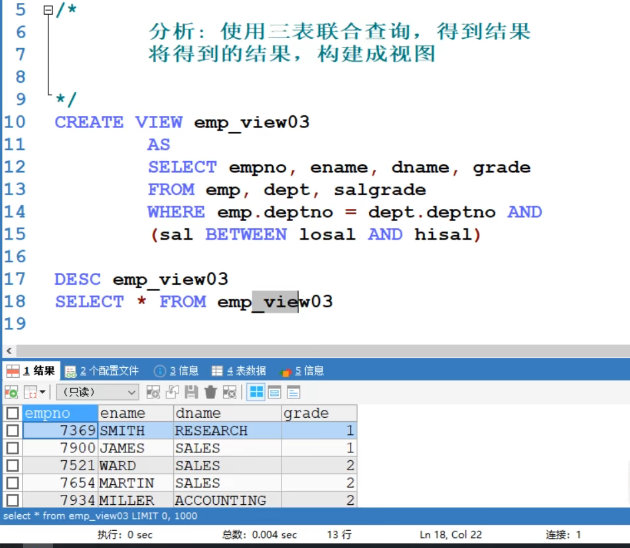
7.视图 - view
视图是虚拟表,其内容由查询定义,同真是表一样,其数据来自真实表(基表)。真是表发生变化,视图数据也发生变化。
- 视图是根据基表来创建(可以创建多个视图),视图是虚拟的表
- 视图也有列,数据来自基表
- 通过视图可以修改基表的数据
- 基表的改变,也会影响到视图的数据
- 场景,只允许查看真实表部分列数据
- 视图中可以做新视图,数据仍然来自基表
7.1 视图操作
1 | 1.创建视图 |
7.2 视图最佳实践

7.3 小练习

8.用户管理
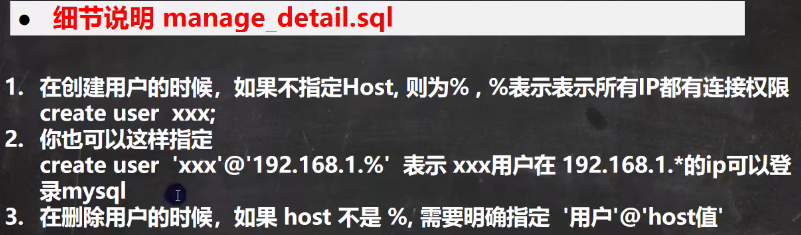
组成:
host:允许登录ip
user:用户名
authentication_string;密码,是通过password()函数加密后的密码
- 根据需要创建不同用户,赋予不同的权限。
8.1 用户管理操作
- 不同权限的用户,登陆后,查看的数据库和数据对象都不相同
1 | 1.创建用户 |
8.2 赋予用户权限 - grant
grant 权限列表 on 库.对象名 to ‘用户名‘@’登录ip’ [identified by ‘密码’];
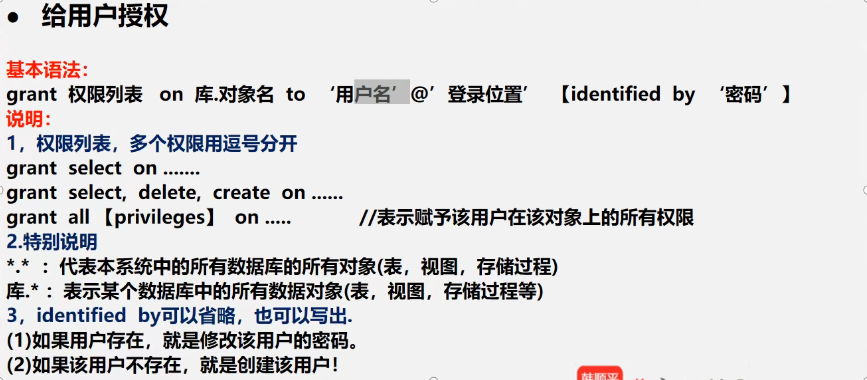
1
2
3
4分配查看、添加news表的权限
grant select, insert
on testdb.news
to 'wang'@'localhost';
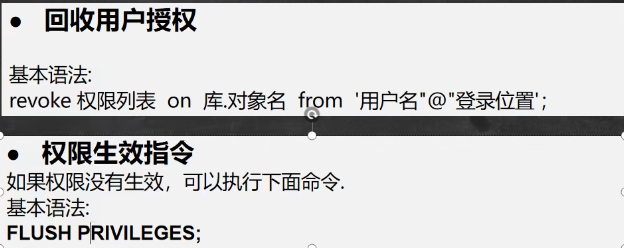
8.3 回收权限 - revoke
1 | revoke select, insert on testdb.news |
8.4 删除用户
- drop user ‘用户名‘@’登录ip’;
10.去除表中重复数据
- 创建临时表temp_tab
- 使用distinct关键字去重数据放入临时表
- 清除原表数据,将临时表数据复制到原表中,删除临时表
1 | create table temp_tab like tab01; |

